普通索引与唯一索引的选择问题
说到这个问题之前,首先我们需要先了解一下change buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
需要说明的是,虽然名字叫作 change buffer,实际上它是可以持久化的数据。也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上。
将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。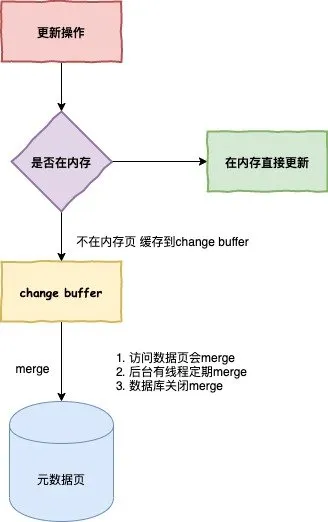
显然,如果能够将更新操作先记录在 change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用 buffer pool 的,所以这种方式还能够避免占用内存,提高内存利用率。
那么,什么条件下可以使用 change buffer 呢?
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入 (4,400) 这个记录,就要先判断现在表中是否已经存在 k=4 的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用 change buffer 了。
因此,唯一索引的更新就不能使用 change buffer,实际上也只有普通索引可以使用。
change buffer 用的是 buffer pool 里的内存,因此不能无限增大。change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
因为 merge 的时候是真正进行数据更新的时刻,而 change buffer 的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做 merge 之前,change buffer 记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
回到我们开头的问题,普通索引和唯一索引应该怎么选择。其实,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。所以,我建议你尽量选择普通索引。